JAX-ALFA Performance Benchmarks: Hardware Platform Comparison
Last updated: May 2026
This notebook compares JAX-ALFA wall-clock performance across hardware platforms (GPUs and CPUs) for a selected set of configurations. Rather than sweeping the full run matrix, a fixed reference configuration is used so that hardware differences are the only variable.
Per-platform full sweeps (all resolutions, SGS models, precisions) are reported separately in the platform-specific benchmark notebooks (e.g. Benchmark_A100).
The primary metric is time per iteration (ms/iter). Speedup is expressed relative to the A100 (80 GB) baseline.
Hardware
Platform label |
System |
Type |
Device |
Memory / Cores |
|---|---|---|---|---|
A100 (80 GB) |
NVIDIA DGX Cloud |
GPU |
NVIDIA A100 Tensor Core GPU |
80 GB HBM2e |
RTX 6000 Ada |
HAL (Lambda workstation) |
GPU |
NVIDIA RTX 6000 Ada Generation |
48 GB GDDR6 |
RTX A6000 (Chaos) |
Chaos (AMD EPYC workstation) |
GPU |
NVIDIA RTX A6000 (Ampere) |
48 GB GDDR6 |
Xeon w9-3495X |
HAL (Lambda workstation) |
CPU |
Intel Xeon w9-3495X |
56 cores / 112 threads |
Selected Configurations
Cross-platform runs use the following fixed configurations:
Resolution |
SGS model |
Precision |
|---|---|---|
\(128^3\) |
LASDD-SM |
SP |
\(128^3\) |
LASDD-SM |
DP |
These configurations are run for all available cases on each platform. Additional configurations can be added to SELECTED_N, SELECTED_SGS, and SELECTED_PREC below.
Setup
[1]:
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
plt.rcParams.update({
'text.usetex': True,
'font.size': 14,
'axes.labelsize': 16,
'xtick.labelsize': 12,
'ytick.labelsize': 12,
})
Repository root, platform directories, and filter
[2]:
def find_repo_root(start=None):
path = Path(start or ('__file__' in globals() and __file__) or Path.cwd()).resolve()
for candidate in (path, *path.parents):
if (candidate / 'examples').is_dir() and (candidate / 'docs').is_dir():
return candidate
raise FileNotFoundError('Could not locate JAXALFA0.1 repository root')
BaseDir = find_repo_root()
print(f'Repository root: {BaseDir}')
# Register all platforms here (GPUs and CPUs).
# Directories that do not exist are silently skipped.
PLATFORM_DIRS = {
'A100 (80 GB)': BaseDir / 'examples',
'RTX 6000 Ada': BaseDir / 'examples_A6000ada',
'RTX A6000 (Chaos)': BaseDir / 'examples_A6000',
'Xeon w9-3495X': BaseDir / 'examples_XeonW9',
}
# Reference platform for speedup calculations
REFERENCE_PLATFORM = 'A100 (80 GB)'
# Configurations included in the cross-platform comparison
SELECTED_N = [128] # grid sizes
SELECTED_SGS = ['LASDD-SM'] # SGS model labels
SELECTED_PREC = ['SP', 'DP'] # precisions
Repository root: /Users/sukantabasu/Dropbox/Codes/LES/JAX-ALFA/JAXALFA0.1
Data loading
[3]:
_DIR_RE = re.compile(
r'(?P<nx>\d+)x(?P<ny>\d+)x(?P<nz>\d+)'
r'_(?P<dyn>LAD|LASDD)'
r'_(?P<base>SM|WL)'
r'_(?P<prec>SP|DP)$'
)
_TIME_RE = re.compile(r'Total Elapsed Time:\s+([\d.]+)\s+seconds')
_ITER_RE = re.compile(r'Finished Iteration\s+(\d+)\s*/\s*(\d+)')
def parse_run_log(log_path):
"""Return (total_seconds, total_iterations) from run.log, or None.
Uses the last entry in the file (most recent completed run).
"""
text = log_path.read_text(errors='replace')
all_times = _TIME_RE.findall(text)
if not all_times:
return None
total_sec = float(all_times[-1])
iters = _ITER_RE.findall(text)
if not iters:
return None
last_done, last_total = int(iters[-1][0]), int(iters[-1][1])
if last_done < last_total:
return None
return total_sec, last_total
def scan_platform(examples_dir, platform_label):
records = []
for log_path in sorted(examples_dir.glob('*/runs/*/run.log')):
run_dir = log_path.parent
run_name = run_dir.name
case = run_dir.parent.parent.name
m = _DIR_RE.match(run_name)
if not m:
continue
result = parse_run_log(log_path)
if result is None:
continue
total_sec, total_iters = result
nx = int(m.group('nx'))
dyn_key = m.group('dyn')
base_key = m.group('base')
prec_key = m.group('prec')
sgs_label = f"{dyn_key}-{base_key}"
records.append({
'Platform': platform_label,
'Case': case,
'Resolution': f'{nx}\u00b3',
'N': nx,
'Dynamic proc.': dyn_key,
'Base model': base_key,
'SGS model': sgs_label,
'Precision': prec_key,
'Total iterations': total_iters,
'Total time (s)': round(total_sec, 3),
'Time/iter (ms)': round(total_sec * 1000 / total_iters, 4),
})
return records
all_records = []
for label, path in PLATFORM_DIRS.items():
if path.is_dir():
recs = scan_platform(path, label)
all_records.extend(recs)
print(f'{label}: {len(recs)} completed runs found')
else:
print(f'{label}: directory not found — skipped ({path})')
df_all = pd.DataFrame(all_records)
# Apply cross-platform filter
df = df_all[
df_all['N'].isin(SELECTED_N) &
df_all['SGS model'].isin(SELECTED_SGS) &
df_all['Precision'].isin(SELECTED_PREC)
].copy()
print(f'\nSelected runs for comparison: {len(df)}')
A100 (80 GB): 57 completed runs found
RTX 6000 Ada: 10 completed runs found
RTX A6000 (Chaos): 1 completed runs found
Xeon w9-3495X: directory not found — skipped (/Users/sukantabasu/Dropbox/Codes/LES/JAX-ALFA/JAXALFA0.1/examples_XeonW9)
Selected runs for comparison: 10
Results Table
[4]:
sort_keys = ['Case', 'N', 'SGS model', 'Precision', 'Platform']
df_sorted = df.sort_values(sort_keys).reset_index(drop=True)
display_cols = ['Platform', 'Case', 'Resolution', 'SGS model',
'Precision', 'Total iterations', 'Total time (s)', 'Time/iter (ms)']
styled = (
df_sorted[display_cols]
.style
.format({'Total time (s)': '{:.1f}', 'Time/iter (ms)': '{:.2f}'})
.set_caption('Cross-platform comparison: wall-clock time per iteration')
.set_table_styles([{'selector': 'caption',
'props': [('font-weight', 'bold'), ('font-size', '13pt')]}])
)
styled
[4]:
| Platform | Case | Resolution | SGS model | Precision | Total iterations | Total time (s) | Time/iter (ms) | |
|---|---|---|---|---|---|---|---|---|
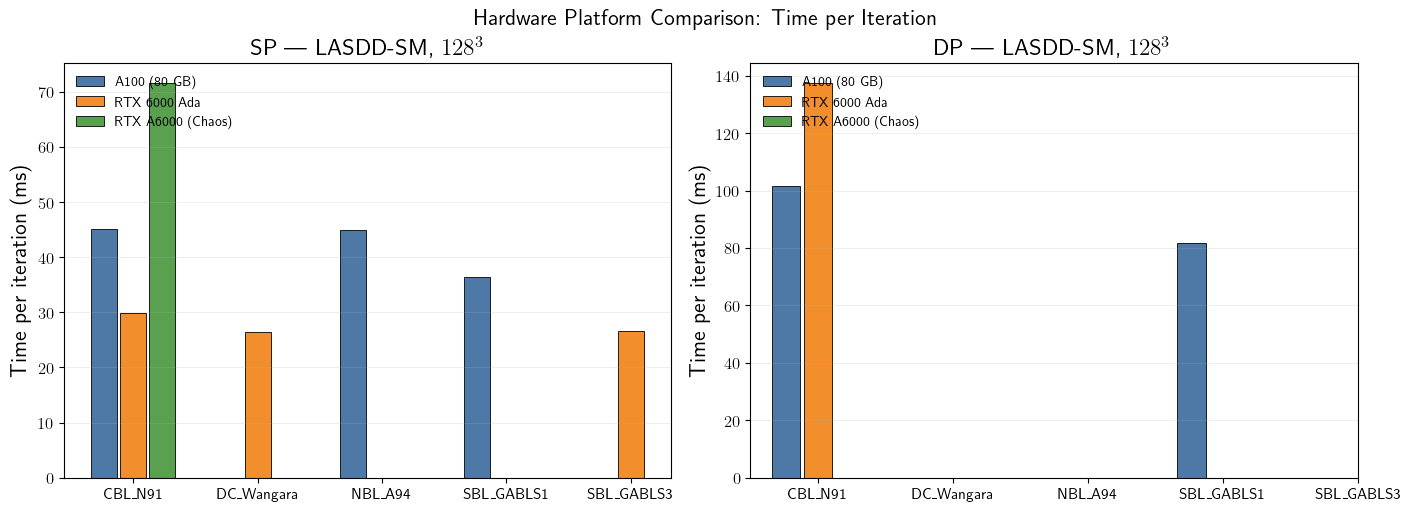
| 0 | A100 (80 GB) | CBL_N91 | 128³ | LASDD-SM | DP | 50400 | 5118.8 | 101.56 |
| 1 | RTX 6000 Ada | CBL_N91 | 128³ | LASDD-SM | DP | 50400 | 6933.8 | 137.58 |
| 2 | A100 (80 GB) | CBL_N91 | 128³ | LASDD-SM | SP | 50400 | 2270.6 | 45.05 |
| 3 | RTX 6000 Ada | CBL_N91 | 128³ | LASDD-SM | SP | 50400 | 1504.6 | 29.85 |
| 4 | RTX A6000 (Chaos) | CBL_N91 | 128³ | LASDD-SM | SP | 50400 | 3611.5 | 71.66 |
| 5 | RTX 6000 Ada | DC_Wangara | 128³ | LASDD-SM | SP | 172800 | 4557.4 | 26.37 |
| 6 | A100 (80 GB) | NBL_A94 | 128³ | LASDD-SM | SP | 300000 | 13505.4 | 45.02 |
| 7 | A100 (80 GB) | SBL_GABLS1 | 128³ | LASDD-SM | DP | 324000 | 26538.9 | 81.91 |
| 8 | A100 (80 GB) | SBL_GABLS1 | 128³ | LASDD-SM | SP | 324000 | 11819.6 | 36.48 |
| 9 | RTX 6000 Ada | SBL_GABLS3 | 128³ | LASDD-SM | SP | 324000 | 8610.7 | 26.58 |
Time per Iteration by Platform
Grouped bar chart showing time per iteration for each case and precision, with one bar per hardware platform (GPU or CPU).
[5]:
platforms_present = df_sorted['Platform'].unique()
cases_present = sorted(df_sorted['Case'].unique())
precisions = ['SP', 'DP']
platform_colors = {
'A100 (80 GB)': '#4e79a7',
'RTX 6000 Ada': '#f28e2b',
'RTX A6000 (Chaos)': '#59a14f',
'Xeon w9-3495X': '#e15759',
}
fig, axs = plt.subplots(1, len(precisions), figsize=(7 * len(precisions), 5),
constrained_layout=True, sharey=False)
for ax, prec in zip(axs, precisions):
sub = df_sorted[df_sorted['Precision'] == prec]
n_groups = len(cases_present)
n_plat = len(platforms_present)
bar_width = 0.7 / max(n_plat, 1)
x = np.arange(n_groups)
for i, plat in enumerate(platforms_present):
vals = []
for case in cases_present:
row = sub[(sub['Platform'] == plat) & (sub['Case'] == case)]
vals.append(row['Time/iter (ms)'].values[0] if not row.empty else np.nan)
offset = (i - n_plat / 2 + 0.5) * bar_width
ax.bar(x + offset, vals, width=bar_width * 0.9,
color=platform_colors.get(plat, '#aaa'),
edgecolor='black', linewidth=0.6,
label=plat)
ax.set_xticks(x)
ax.set_xticklabels([c.replace('_', r'\_') for c in cases_present], fontsize=11)
ax.set_ylabel(r'Time per iteration (ms)')
ax.set_title(f'{prec} --- LASDD-SM, $128^3$')
ax.legend(frameon=False, fontsize=10)
ax.grid(axis='y', alpha=0.3)
fig.suptitle(r'Hardware Platform Comparison: Time per Iteration', fontsize=16)
plt.show()
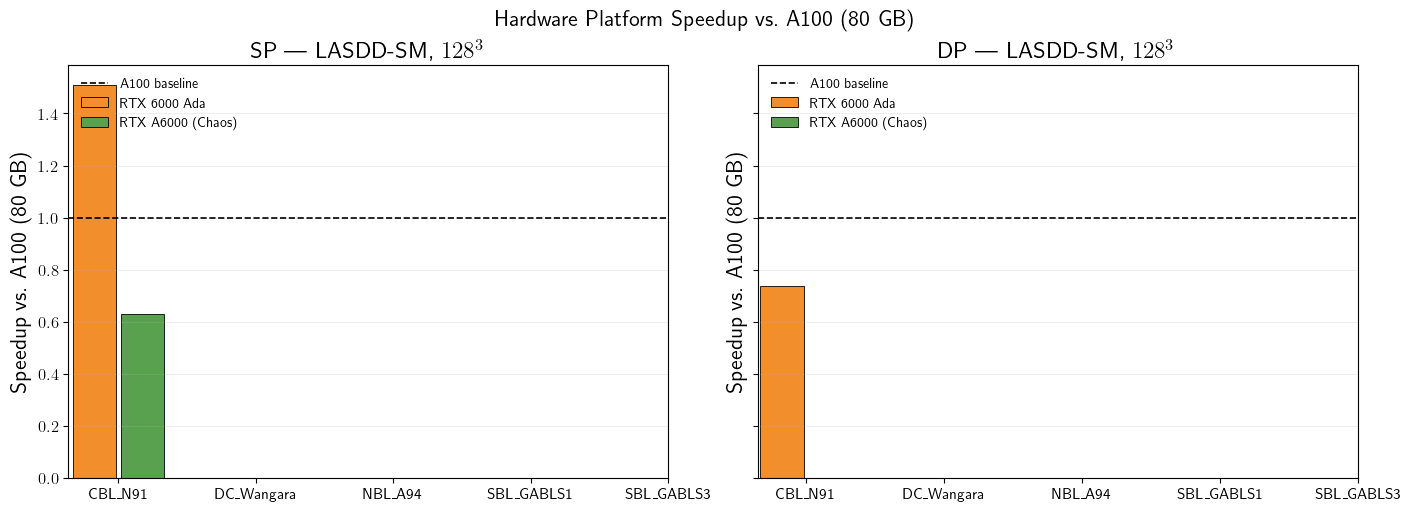
Speedup Relative to A100 (80 GB)
Speedup = \(t_{\mathrm{A100}} / t_{\mathrm{platform}}\) for matched (Case, Resolution, SGS model, Precision) pairs. Values above 1 indicate the alternative platform is faster than the A100 baseline.
[6]:
df_ref = df_sorted[df_sorted['Platform'] == REFERENCE_PLATFORM].copy()
match_keys = ['Case', 'N', 'SGS model', 'Precision']
alt_platforms = [p for p in platforms_present if p != REFERENCE_PLATFORM]
if not alt_platforms:
print('No alternative platforms available yet — register an examples_<platform>/ directory in PLATFORM_DIRS to compare.')
else:
speedup_records = []
for plat in alt_platforms:
df_alt = df_sorted[df_sorted['Platform'] == plat].copy()
merged = df_ref[match_keys + ['Time/iter (ms)', 'Resolution']].merge(
df_alt[match_keys + ['Time/iter (ms)']],
on=match_keys, suffixes=('_ref', '_alt')
)
merged['Speedup'] = merged['Time/iter (ms)_ref'] / merged['Time/iter (ms)_alt']
merged['vs. Platform'] = plat
speedup_records.append(merged)
df_speedup = pd.concat(speedup_records, ignore_index=True)
fig, axs = plt.subplots(1, len(precisions), figsize=(7 * len(precisions), 5),
constrained_layout=True, sharey=True)
for ax, prec in zip(axs, precisions):
sub = df_speedup[df_speedup['Precision'] == prec]
n_groups = len(cases_present)
n_plat = len(alt_platforms)
bar_width = 0.7 / max(n_plat, 1)
x = np.arange(n_groups)
for i, plat in enumerate(alt_platforms):
vals = []
for case in cases_present:
row = sub[(sub['vs. Platform'] == plat) & (sub['Case'] == case)]
vals.append(row['Speedup'].values[0] if not row.empty else np.nan)
offset = (i - n_plat / 2 + 0.5) * bar_width
ax.bar(x + offset, vals, width=bar_width * 0.9,
color=platform_colors.get(plat, '#aaa'),
edgecolor='black', linewidth=0.6, label=plat)
ax.axhline(1.0, color='k', linestyle='--', linewidth=1.2, label='A100 baseline')
ax.set_xticks(x)
ax.set_xticklabels([c.replace('_', r'\_') for c in cases_present], fontsize=11)
ax.set_ylabel(r'Speedup vs.\ A100 (80 GB)')
ax.set_title(f'{prec} --- LASDD-SM, $128^3$')
ax.legend(frameon=False, fontsize=10)
ax.grid(axis='y', alpha=0.3)
fig.suptitle(r'Hardware Platform Speedup vs.\ A100 (80 GB)', fontsize=16)
plt.show()